
type
status
date
slug
summary
tags
category
icon
password
Property
Mar 6, 2024 11:23 AM
Created time
Jan 31, 2024 05:37 PM
本文是《科学计算可视化》课程期末考查作业,作业要求为:
1. 扒取一定数量的社交网站数据, 可以用网站本身公开的API,也可以用扒取工具,也可以用扒取的接口程序
2. 扒取以后,将数据进行整理,以矩阵或者有序文本的方式进行存储
3. 用扒取的数据,实现一个可视化方案。 可以用各种方式,如统计图表、二维、三维、动态等,如果是需要操作的,附带操作说明文档。
4. 可以用各种软件,如Tableau, Gephi,Python, R等。
5. 需要打包发给我的内容,包括a.扒取的数据,b. 扒取数据搜集的代码(如果没有则不用)。c. 随作业提交一份报告,说明你用了什么数据、数据的构成、维度等信息,采用了什么可视化方案,为什么采用这样的方案,可视化图,以及从中说明了什么问题。
实验报告可能存在:强拉因果,无中生有,刻意歪曲/美化事实等情况,请酌情读取。
2022年11月底至12月初,国内防疫政策调整后,各地都在经历这一特殊的过渡阶段,各地居民在2022年12月内经历新冠病毒感染结果阳性的情况十分普遍。通过分析微博这里社交媒体相关数据,有助于了解疫情在空间上和时间上的发展趋势,有助于关切社会舆论热点信息,对个人防疫卫生和政府决策都有一定帮助。
微博数据集的抓取
新浪微博自2022年4月起在博文相关页面开放显示发布微博所对应的IP归属地,对国内用户精确到省份。但是现有微博爬虫相关的开源项目上未见能够爬取微博发布时IP归属地信息的工具,因此我只好自己抓包分析编写代码。
本人爬取了2022年12月1日至12月31日间关键词为“阳了”的微博搜索结果,代码思路是使用python的requests库进行网页请求,先获取搜索结果页面,再通过抓包分析得知的ajax接口请求单独获取每一条微博的信息,使用lxml,json相关库解析并保存数据。
数据最终以csv格式保存,一条微博一行,其信息表头包括微博id、用户id、用户昵称、发布时间、IP归属地、发布工具、转发数、评论数、点赞数和微博正文。
微博的搜索结果最多显示50页,每页一般8条,搜索的时间范围最小为一个小时,因此为了获取尽可能多的微博,我对12月每一天每一个小时范围内的微博进行搜索并解析保存,同时使用tomorrow库进行多线程加速。由于时间紧张,我没有对抓取数据时的出错进行详细处理,只是简单地重试和跳过。
具体代码实现请看下方的weibo_crawl.py文件。该文件依赖库包括requests, lxml, tomorrow3。同时还需要微博用户的cookie信息,因为涉及隐私,本人的cookie在源代码中已隐去。
本实验共计获取了26,3308条微博数据。
关键词“阳了”微博数据在时间和空间上的变化特征
对数据进行可视化,使用折线图和地图绘制观察微博数据的变化,可以从发布量在时间和空间的变化、分布差异上了解疫情的发展态势。
不同省份发布微博数量统计结果
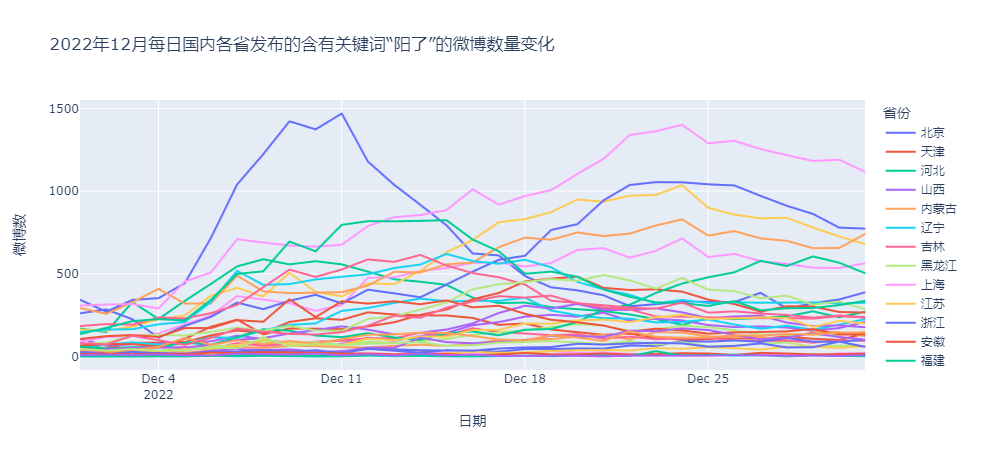
源代码notebook中的图表结果是可交互的,因为线条较多,部分数据线颜色差异小,可在源代码中通过鼠标贴近数据线显示对应省份、时间和微博数。
可以看到12月中上旬北京地区的“阳了”微博数量一枝独秀,中旬四川湖北等地引来小高峰,下旬广东,浙江,山东,浙江,上海等地也迎来高峰,并且热度降低得较北京慢,福建地区的微博数量自12月来不断攀升,虽在12月底有所下降,但是整体仍处在上升趋势。可视化的分析结果符合本人近一个月来的生活认知。
不同省份发布微博数量的地域分布变化
下面使用地图来呈现这一数据的变化,使用到的是pyecharts库
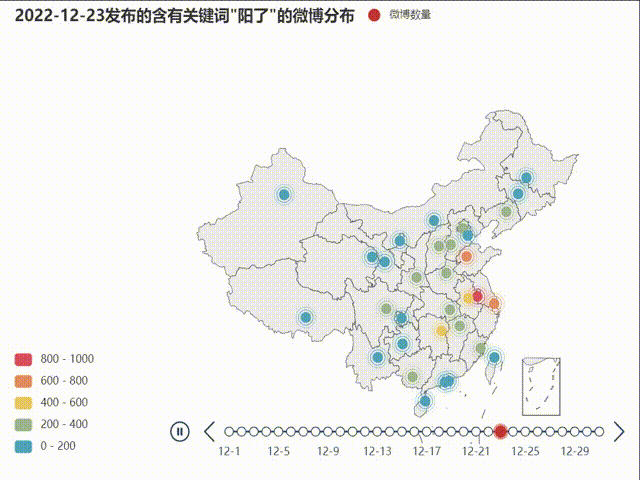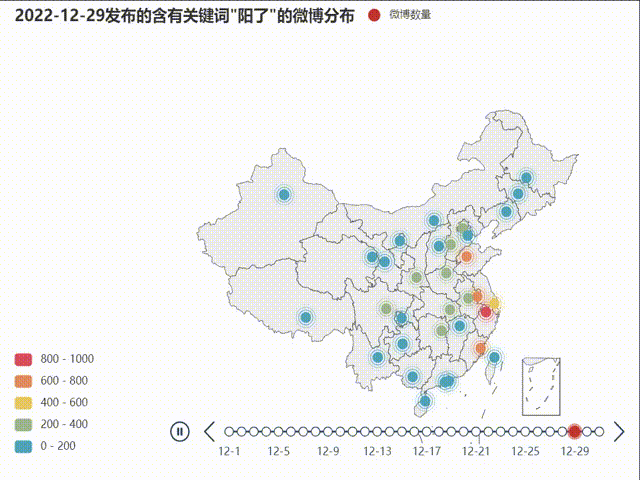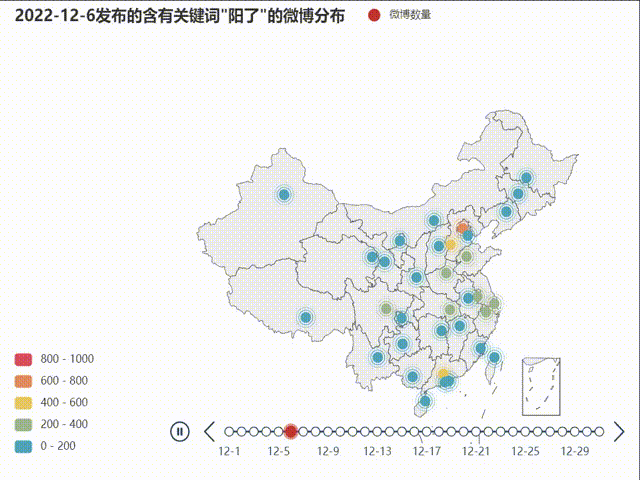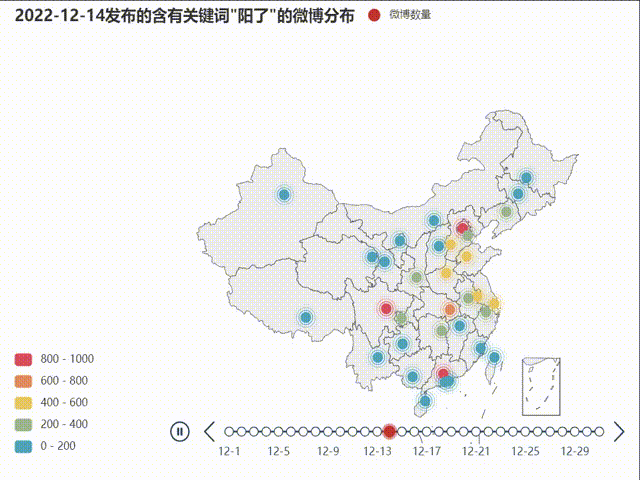
首先需要指出的是在新疆、西藏等欠发达地区或人口基数较低的地区存在微博使用人数少的问题,由此导致了部分地区的数据量少,数据变化和起伏不明显,造成了实验结果的偏差。从动态地图绘制结果来看,疫情的地域分布变化并不非常突出,全国人口密集地都有一定爆发-回落趋势,总体有一定从中部轴线向东部沿海扩散的趋势。
关键词“阳了”微博数据在内容上的特征
下面尝试通过文本聚类相关算法获取群众在社交媒体上表达讨论的内容大致包括哪些主题,并进行可视化分析。
这里使用LDA主题模型进行文本聚类分析和可视化,使用到Mallet(用Java开发的用于 NLP 的机器学习算法包与python下的gensim(自然语言处理工具库)。因此如果需要验证代码,要求设备已安装jdk并配置相关环境变量(下文代码中已设置环境变量)。同时还需要jieba分词工具。
简单清理掉数据集中一些可能存在的特殊字符
逐行调用jieba分词
读取并去除分词结果中的停用词
构建 bigram 或者 trigram 的步骤进行高频连词组合,可以把一些高频连词组通过连字符合成一个单词。比如原来分词结果【bzier】与【曲线】总是一同出现,合并后成为【bzier_曲线】。
LDA 算法的输入主要包括分词词典(id2word)以及向量化表示的文本,下面corpus的输出内容表示第几个单词出现了多少次,例如 (0,1)表示第 0 个单词在该段文本中共出现了 1 次,而每个序号的单词保存在id2word。
构建LDA模型,这里我将数据集分成5个主题,下方代码在我的设备上需要运行约18分钟,因为数据集较大,运行时间长,我就没有对不同的主题划分数结果进行模型评估比较优选了。
我们对生成的模型进行主题内容的输出,下方代码输出了同一主题下出现次数最多的词,即得分高的词汇.
下面对主题划分数为5的LDA模型进行展示分析如下:
LDA模型文本主题划分的可视化分析
pyLDAvis是一个开源python库,它有助于分析和创建由LDA创建的聚类结果的高度交互式可视化。
下面对主题划分数为5的模型进行展示分析如下:
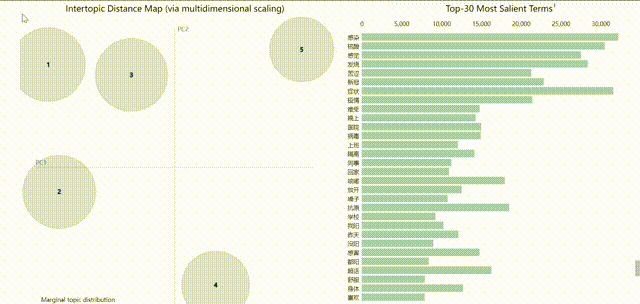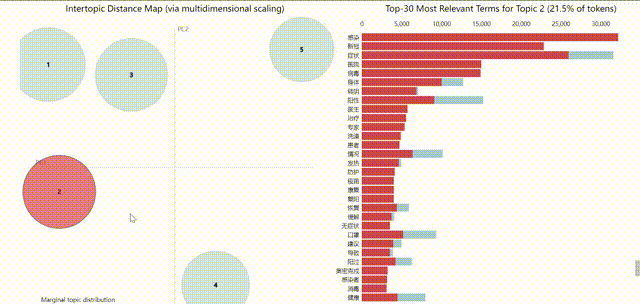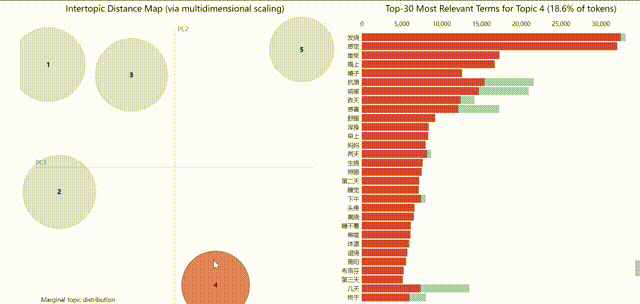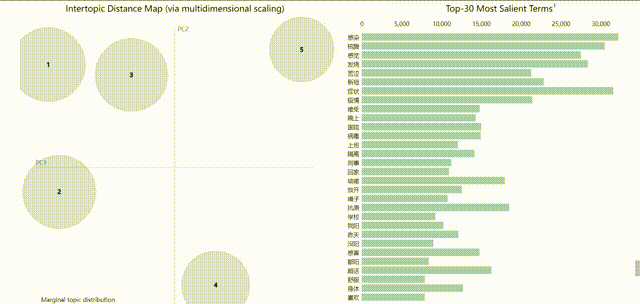
受限于GIF大小,上图较模糊,可在源代码notebook中直接查看,获得更佳体验。pyLDAvis的可视化结果是可交互的,左边的气泡分布代表的是不同主题,所以气泡的大小及编号对应了在该数据集中主题出现的频率。
将鼠标移至气泡所在位置,右侧会显示该主题内得分最高的前几个特征词。浅蓝色的表示这个词在整个文档中出现的频率(权重),深红色的表示这个词在这个主题中所占的权重。
右上角可以调节一个参数λ(截图时没截进来),用于调节权重计算方法。鼠标拖动参数条即可看到权重排名的变化。计算方法为:
- 如果λ接近1,那么在该主题下更频繁出现的词,跟主题更相关;
- 如果λ越接近0,那么该主题下更特殊、更独有的词,跟主题更相关(有点类似TF-IDF)
我将λ调节至0.6以兼顾关键词频度与独特关键词,由此可以观察每个主题的不同关键词,得到一个大致的分类结果如下:
- 国家防疫政策相关
- 新冠防治相关
- 积极情绪相关(似乎是一类和疫情不太相关的数据)
- 个人感染病程相关
- 生活工作及情绪相关
值得注意的是主题3应该代表了阳光积极向上的情绪等含义,这是“阳了”一词过去可能更相关的领域。
pyLDAvis工具使用多维尺度分析,提取出主成分(这个主成分到底指代什么我没有深入了解)做维度,将主题分布到这两个维度上,主题相互之间的位置远近,就表达了主题之间的接近性。气泡距离采用的是JSD距离,(应该)可认为是主题间的差异度,气泡有重叠说明这两个话题里的特征词有交叉。可以看到在该方案下各个主体之间的重叠度并不大,表现尚可。
实际上所进行划分的微博数据基本上都是在“新冠疫情”这一大主题下的,使用文本聚类、主题划分相关的可视化方法有点为难相关算法模型,但总的来说划分结果还是具有一定区分度的,主题划分的可视化结果也有助于更多维、有侧重地了解当下疫情相关社会舆论信息。
实验总结
通过上述数据可视化分析,我们可以获得以下信息:
- 不同省份在2022年12月新冠疫情爆发的时间节点有差异,更多省份在12月中下旬迎来一轮高峰,不少地区至今仍处在高峰附近或正在不断增长。
- 单纯通过关键词“阳了”的微博发布数统计结果并不能很好地评估疫情在地域层面的传播情况。
- 从内容上,国家防疫政策相关主题的核心关键词是“核酸”;个人感染病程相关内容的核心关键词是“发烧”;生活工作及情绪相关内容的核心关键词是“苦涩”,不过这是微博上的一个表情对应名称,重复表情是在博文很常见的现象,因而会导致聚类结果出现一定偏颇。不过这也一定程度反映了群众这段时间生活质量与精神状态欠佳。
- 作者:叶修齐
- 链接:https://notion.siuze.top/article/af2e6f7b-0ef7-4249-b195-85a5be2791d2
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。